
声明:
这篇论文还未读,所以里面所有内容都是来自于各种网络大佬的理解,等自己读了论文后有待补充。
为什么要提出Focal-loss
现在目标检测大概分为两种: one-stage和two-stage,one-stage虽然速度快,但是精度不如two-stage的,相反,two-stage虽然精度高,但是速度慢,后来Lin等人对于此问题的研究发现,one-stage的精度不高与训练时后景数据相比于前景数据少的多有很大原因,因此Lin等人通过对交叉熵损失函数进行修改,提了Focal-loss,即会特别关注某些Loss的意思。
论文分析了One-stage精度不高的原因
- 正负样本极度不均衡:anchor的生成是用类似于sliding-windows的方式,这会导致正负样本的比例接近1:1000,而且绝大多数负样本为“easy example”;
- 梯度优化过程中被easy example过度影响: 根据交叉熵损失函数,虽然easy example的Loss不高,但是数量多,所以在梯度优化时Loss函数会过度关注这些easy example,从而使得那些难以分类的类别得不到很好的训练。
对于Focal-loss 的理解
首先回顾一下交叉熵损失函数:
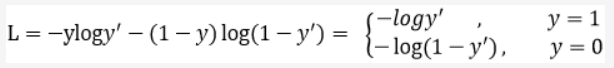
其中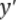 是经过激活函数的输出,在0-1之间,所以普通的交叉熵就是正样本的输出概率越大,那么Loss就越小,对于负样本,输出概率越小,Loss就越小。
是经过激活函数的输出,在0-1之间,所以普通的交叉熵就是正样本的输出概率越大,那么Loss就越小,对于负样本,输出概率越小,Loss就越小。再看加了gama后的Loss函数:
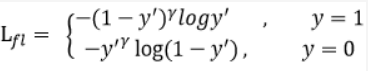
在加入了gama后,就对难易样本的loss有了区分,对于正样本而言,如果输出为0.9,那么表明这个样本是容易训练的,所以Loss就变得比原来小,如果输出是0.5,表明难以训练,所以Loss就大,所以就使得Loss函数更加关注难训练的样本,所以减少了easy example的影响,论文实验发现gama=2是最优的。Focal-loss的最终版本:
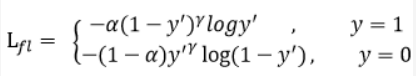
α的加入实际上是使交叉熵加权,α一般设置为类别比例的倒数或者直接设为超参数(人为设定),这样使得正样本(数量少)得到Loss的重视,从而减少负样本的影响。为什么Focal loss没有用在two-stage上
- two-stage会在生成区域建议阶段来使用NMS,使得候选框大量减少,在此过程中,减少了大量的背景框;
- 训练时用minibatch的采样策略,比如Faster-rcnn使用正负样本为1:3,这实际上起到了α 的作用。