
Introduction
在CenterNet中,作者找到了更简单、更有效的方法,作者用bbox的中心点来代替此物体,其他特征,比如物体大小,维度,姿态等等则从物体中心点位置的图像特征来直接回归,所以目标检测就变成了关键点的预测问题。一开始将图像输入到一个全卷积中,然后生成一个热图,热图中的峰值就对应于物体的中心点,每个峰值的图像特征就用于预测物体bbox的高和宽,训练用标准的密集监督学习,推理过程是一个单一的向前传播,没有NMS的后处理。
Related work
CenterNet方法近似相当于锚点为基准的one-stage方法。
- CenterNet仅仅根据位置来分配’anchor’,而不是根据框重叠,也就是说,CenterNet的’anchor’仅仅会出现在当前目标的位置处而不是在整个图上都分配,所以不用手动调阈值来看框是正类还是负类;
- 每个物体只有一个正框,所以不需要NMS来后处理,只需要在关键点热图上提取峰值;
- CenterNet输出的下采样因子是4,所以输出分辨率相比其他框架来说更大,这样就消除了对于多重锚点的需求;
疑问:多重锚点是什么意思??(原文是‘This eliminates the need for multiple anchors’)
Preliminary
假设输入图像的维度为(3 , W , H),那么目标就是生成一个热图,Y∈[0,1] ,其中Y的维度是(C , W/R , H/R),C在目标检测中是类别,论文用coco数据集,所以C=80,论文中作者取R=4,表示下采样的步幅是4,那么为什么要生成这样一个热图呢,原来这个三维张量Y中的每一个值如果是1的话,那么代表这是检测的关键点,如果是0的话代表的是背景,所以Y的值要在0和1之间,表示概率,论文中用了几种不同的encoder-decoder networks来预测图像中的Y:
- Hourglass Network
- 带有转置卷积的ResNet
- 原始的DLA和作者改造后的DLA;
在训练过程中,CenterNet学习了CornerNet的方法,对于每个ground truth 的某一类C,我们需要把p(中心点)计算出来进行训练,计算方法为p = ((x1 + x2)/2 ,(y1 + y2)/2),对于下采样后的坐标,我们设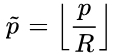 ,其中R为下采样因子,并且向下取整,所以最终计算出来的中心点是对应低分辨率的中心点。有了中心点的坐标后,接下来的任务就是如何根据gt关键点的坐标来生成热图,作者用了一个高斯核
,其中R为下采样因子,并且向下取整,所以最终计算出来的中心点是对应低分辨率的中心点。有了中心点的坐标后,接下来的任务就是如何根据gt关键点的坐标来生成热图,作者用了一个高斯核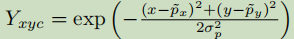 来将计算好的关键点分布到如图中,其中 σp是一个对物体大小自适应的标准差。这样就生成了一个热图
来将计算好的关键点分布到如图中,其中 σp是一个对物体大小自适应的标准差。这样就生成了一个热图
疑问:px和py都是整数,那么x和px 在计算高斯核的时候是如何匹配的??或者对于高斯核的理解一开始就是错的??
损失函数
重点看一下损失函数:
中心点预测的损失函数
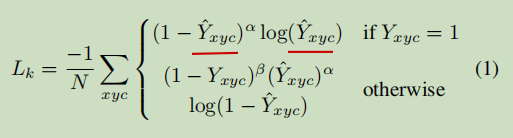
作者对于中心点位置和类别的预测是通过Focal-loss来进行逻辑回归的, α and β是超参数,论文中α=2,β=4,N是图像中关键点的个数,目的是将Focal-loss归一化。
疑问:N的数量是不多的,但是Lk是对所有的点来算损失函数的,那么为什么N可以将Focal-loss归一化??
目标中心的偏置损失
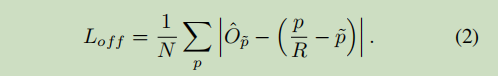
由于对于图像进行了R=4的下采样,但是中心点最终是要映射回原图的,这样会有精度损失,因此,对于每一个中心点,都额外采用一个局部偏移量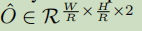 ,根据维度也可以看出,对于同一位置的所有类别,这个局部偏移量是共享的。注意上面的损失函数仅仅是对于关键点位置来算的,其他的点是要被忽略的。
,根据维度也可以看出,对于同一位置的所有类别,这个局部偏移量是共享的。注意上面的损失函数仅仅是对于关键点位置来算的,其他的点是要被忽略的。
疑问: 1. 中心点最终是如何映射到原图的??是简单的乘4?? 2. 为什么局部偏移量要对所有类进行共享??是为了减少计算量?? 3. 这个偏移量是在缩小后的图像上的偏移,但是在原图上的偏移和这个偏移应该是不一样的吧?? 4. 回归的目的不就是为了减少偏移量吗?那为什么还要算偏移损失??
目标大小的损失
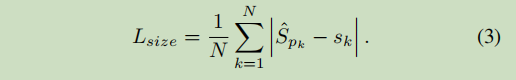
假设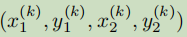 是Ck类的目标k的bbox,那么中心点的坐标就是pk =
是Ck类的目标k的bbox,那么中心点的坐标就是pk = 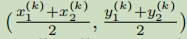 ,我们用Y^来预测所有的关键点,然后对每个目标k的size 进行回归,Sk =
,我们用Y^来预测所有的关键点,然后对每个目标k的size 进行回归,Sk = 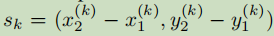 ,这是下采样后的长宽值,
,这是下采样后的长宽值,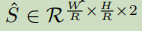 是预测值,由维度可知,这是所有的类别共享的size值。
是预测值,由维度可知,这是所有的类别共享的size值。
疑问:为什么所有的类都在一个中心点出有相同的size??
总的损失函数为:
论文中 λsize = 0.1, λoff = 1。
最终每个坐标点产生C+4个数据,分别是类别、长宽和偏移量,这三个量是用一个单独的网络来预测出来的,并且所有的输出共享一个backbone网络。
推测阶段
在预测阶段,首先对一张图像进行下采样,然后在下采样的特征图中对每个类预测中心点,然后就可以把输出图中每个类的热点单独提取出来,提取过程是什么呢,首先,可以检测当前热点的值是否比周围八个邻近的热点都大,然后提取出100个这样的点,方式是3x3的Maxpool,类似于NMS。最后,通过预测点算出来的Y^,代码中设置阈值为0.3,将这100个点中大于0.3的作为最终要的结果。这样,有了中心点的位置后就可以生产锚框了。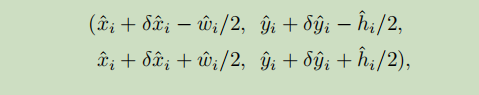
即变成(x1 , y1 , x2 , y2)的锚框