
10. 正则表达式匹配
https://leetcode-cn.com/problems/regular-expression-matching/
方法1
如果没有的话,那么就是一个字符一个字符匹配,但是有\的存在使得问题变得复杂。而题目中说*可以匹配0个、1个和多个字符,所以我们要分情况讨论。我们必须把*和其前面的字符看做一个整体。设$p[j+1]$为*
- 如果$p[j]\ != s[i]\ and\ \ p[j] != ‘.’$,那么$p[j]p[j+1]$必须只匹配0个,进而转到$p[j+2]$,与$s[i]$进行匹配,不然没法保证匹配;
- 如果$p[j] == s[i]\ \ or \ \ p[j] == ‘.’$,那么我们就要考虑到底要匹配几个。
1 | // 方法1,递归 |
这是一种暴力的做法,会超时。
方法2
我们可以发现,要判断$p[0 , … , j]$和$s[0 , … , i]$是否匹配,与二者的子串是否匹配有关。
我们设$dp[i][j]$表示$p[0 , … , j-1]$和$s[0 , … , i-1]$是否匹配,是一个bool型数组。
1 | class Solution { |
问题1:为什么匹配多个时看$dp[i-1][j]$?
$dp[i-1][j]$表示的是$p[0,…..,j-1]$和$s[0,…..,i-2]$是否匹配,而$dp[i][j]$表示的是$p[0,…..,j-1]$和$s[0,…..,i-1]$是否匹配,两者只差一个$s[i-1]$,此时我们已经判断出$p[j-1] == s[i-1]$。其实当$dp[i-1][j] == 1 \ and \ dp[i-1][j-1] == 0$的时候才是真正的多个。
问题2:为什么$dp[i-1][j-1]$不需要判断?
我们可以发现:如果$dp[i-1][j-2]$成立,那么$dp[i-1][j]$一定成立,因为此时$dp[i-1][j]$可认为是在$dp[i-1][j-2]$的基础上匹配了0个,由真值表可知,通过判断$dp[i-1][j]$就可以判断出$dp[i-1][j] \ or \ dp[i-1[j-2]$的值。
523. 连续的子数组和—-前缀和+哈希表
https://leetcode-cn.com/problems/continuous-subarray-sum/
这道题和560. 和为K的子数组题有点相似,不同的是这道题要求数组大小至少为2,而且和是$k$的倍数,即和为$n*k$,其中$n$可以为0和负数。
我们可以这样想:如果存在$array[i…..j]$,使得$sum[i….j] == n*k$,那么有:
我们令 $sum[0….i-1] == x_1k+y_1$,$sum[0….j] == x_2k+y_2$,且$0 < y_1 < k \ and \ 0 < y_2 < k$所以有:
所以$y_1 == y_2$
这样,我们就可以知道:当存在$i-1 < j-1$,其$sum \div k$相等,那么就找到了解。
1 | class Solution { |
1012. 至少有 1 位重复的数字——数位dp
https://leetcode-cn.com/problems/numbers-with-repeated-digits/
这道题求至少有1位重复数字的正整数的个数,但是至少很难搞,所以我们转化成求没有重复数字的正整数个数。
所以,我们找到了筛选目标:
- 没有重复数字
- 注意前导零,比如0010看做10
数位dp需要我们搞清楚每一位的状态。这道题每一位的状态很显然是其前几位的数字的排列组合。
1 | class Solution { |
本题数位dp在哪里进行了剪枝?
答案就在记忆化中,我们考虑每一位的状态是考虑本位的前几位的数字的排列组合,比如12_ _ 和21_ _,我们在虽然两个数不同,但是第三位的状态是相同的,都是$dp[2][(0000000110)_2]$(我的位数是从0开始的),即同一组数的不同排列组合是一种状态, 那么我们在算21··时直接记忆化就行了。
53. 最大子序和
https://leetcode-cn.com/problems/maximum-subarray/
方法1:简单dp
求以每个数为右端点的最大子数组和
1 | class Solution { |
方法2:分治
让我想起了归并排序,也是分治思想。就是一个数组$[l,r]$可分为$[l,m]$和$[m+1,r]$这两个子区间,其中$m = (l+r)/2$,$[l,r]$中的最大子数组的和就可以通过$[l,m]$和$[m+1,r]$来求,直到$l == r$时,即每个子区间只有一个元素是,表示递归到了最深处。
那么,如何通过两个子区间来求$[l,m]$的最大值呢?
我们先设出变量:
- $msum$表示区间的最大子数组和
- $lsum$表示区间中以区间左端点为子数组左端点的子数组的最大和
- $rsum$表示区间中以区间右端点为子数组右端点的子数组的最大和
- $isum$表示区间的所有元素的和
我们可以这样想,由于题目要求是连续的数组和,所以区间的$msum$要么在左区间内,要么在右区间内,要么一半在左区间,一半在右区间,前两种好说,即$msum = max(l_msum , r_msum)$,最后一种就需要变量$lsum$和$rsum$了,即左边一半是$l_rsum$,右边一半是$r_lsum$。
再说说$lsum$和$rsum$怎么维护。以$lsum$为例:有两种情况:
- 如果$l_lsum$没有覆盖所有的左区间,那么只能是$lsum == l_lsum$
- 如果$l_lsum$覆盖了所有的左区间,即$l_lsum == l_isum$那么就要考虑右区间了,考虑到连续性,我们只能考虑$r_lsum$,所以$lsum == max(l_lsum , l_lsum + r_lsum)$
最后$isum == l_isum + r_isum$
1 | class Solution { |
546. 移除盒子
https://leetcode-cn.com/problems/remove-boxes/
是真的难,毫无思路。
方法:区间dp
设$dp[i][j][k]$。其中$k$表示区间$[i,j]$的前面有$k$个箱子的颜色和第$j$个箱子的颜色相同。$dp$的值表示区间$[i,j+k]$个箱子最大能获得的分数。
我们用一个例子来说明:
我们考虑下面一堆箱子:一开始是$dp[0][8][0]$
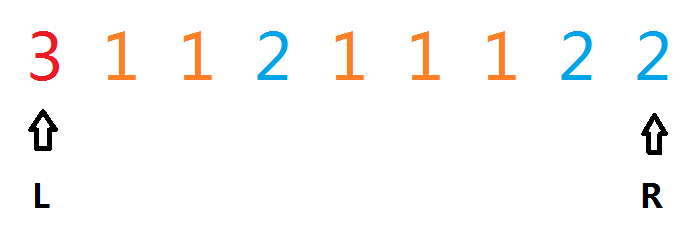
但是我们发现:上图的$dp[0][8][0] == dp[0][7][1]$
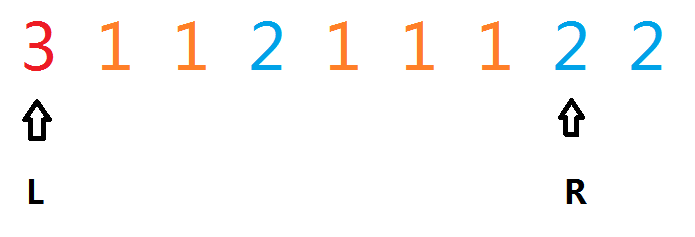
所以我们的第一步就是移动$R$指针,使得$K$最大。到这里,我们就有了选择:
- 要么把最后的两个2和前面的若干个2排在一起,即把4,5,6这些1去掉
- 要么干脆不排2了,直接去掉最后两个2
第一种情况:我们把$L$和$R$中间的1去掉,得到$dp[0][3][2] + dp[4][6][0]$
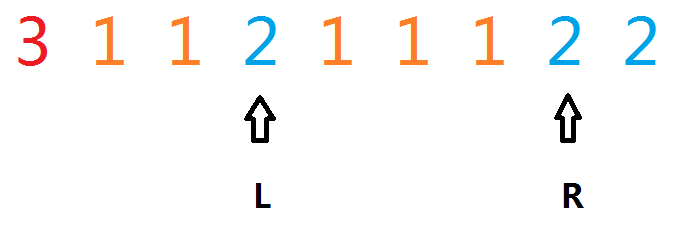
第二种情况:去掉最后两个2,得到$dp[0][6][0] + 2*2$
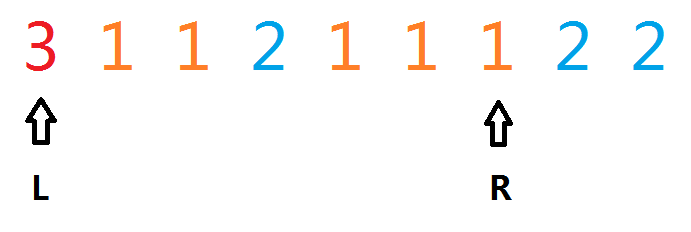
然后一直dfs递归。
思路:
其实当我们遇到图2的情况时,我们只能有两种选择,一种是直接去掉,一种是和后面的若干个与它相同颜色的箱子排在一起
1 | class Solution { |
疑问:代码中情况1中为什么得到一个$boxes[i] == boxes[r]$就进行递归,而不是找到最大的$i$后进行一次递归?
当时有这个疑问的原因是假设一个序列:1 1 2 2 1 1 1 2 2,为什么$i$在2的位置就递归而不是在3的位置递归,虽然情况1是用for循环来解决这一问题,但是这不是多此一举吗?
1 | //疑问代码: |
但是如果看序列:3 2 2 2 3 4 3,就会发现,如果我们想得到3 3 3,那么用上面的代码$i$在0的位置就递归然后break了,这就是错的,然而我们如果一直往后找当$i == 3$时,就会得到3 3 3,所以正确修改的代码:1
2
3
4
5
6//上面的代码将break去掉(虽然最后没快多少)
for(int i = l ; i < r ; ++i){
if(boxes[i] == boxes[r] && (boxes[i+1] != boxes[r] || i == r-1)){
nums[l][r][k] = max(nums[l][r][k] , dfs(boxes , i+1 , r-1 , 0) + dfs(boxes , l , i , k+1));
}
}
576. 出界的路径数
https://leetcode-cn.com/problems/out-of-boundary-paths/
方法1:dfs+记忆化
这个没什么好说的,常规思路
1 | class Solution { |
方法2:dp
我们定义$dp[k][i][j]$为在$[i,j]$处只剩下$k$步时最大可以出界的个数。
因为球是可以往回走的,所以在一个坐标处的$k$可以是$[0,1…..N]$,其中0的时候可以不考虑。那么我们在坐标$[i,j]$处最多可以出界的个数就是:
1 | class Solution { |
疑问:为什么只在’已经出界而且是0步时是1’,k!=0时出界就不算了?
1 | //疑问代码:修改初始化 |
上面的代码是错误的,原因是造成了重复,我们其实只算的是坐标$[i,j]$在$k=0$时恰好走到了边界的个数的路径,即如果一个坐标$[i,j]$在某一边界有步数$K == k$时就能走出去,那么对于所有的$step > k$都能从这个边界沿着相同的路径走出去。所以我们算的是在$N$步内能走出界的路径数,不一定一个路径要走完$N$步。
1049.最后一块石头的重量2
https://leetcode-cn.com/problems/last-stone-weight-ii/
这道题求返回石头的最小重量,也就是说,两个相撞的石头$x$和$y$重量越接近越好。那么我们就可以将问题转化为将一堆石头分为两堆,这两堆石头的重量越接近越好,即尽可能地接近这堆石头总重量的一半。
那么我们可以想到用0-1背包问题来求解,即一堆石头装入容量为$sum/2$的背包,求背包最大能装多少,这里的$value$和$weight$是相同的。
1 | class Solution { |
1039. 多边形三角剖分的最低得分
https://leetcode-cn.com/problems/minimum-score-triangulation-of-polygon/
方法一:dfs+记忆化
我们设$dp[i][j]$表示区间$[i,j]$内能得到的最低分
1 | class Solution { |
方法二:区间dp
1 | class Solution { |