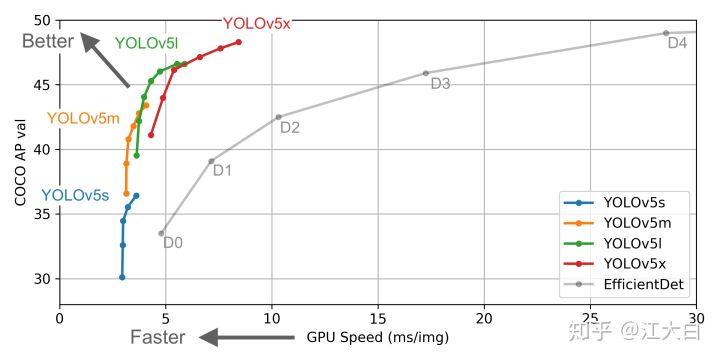
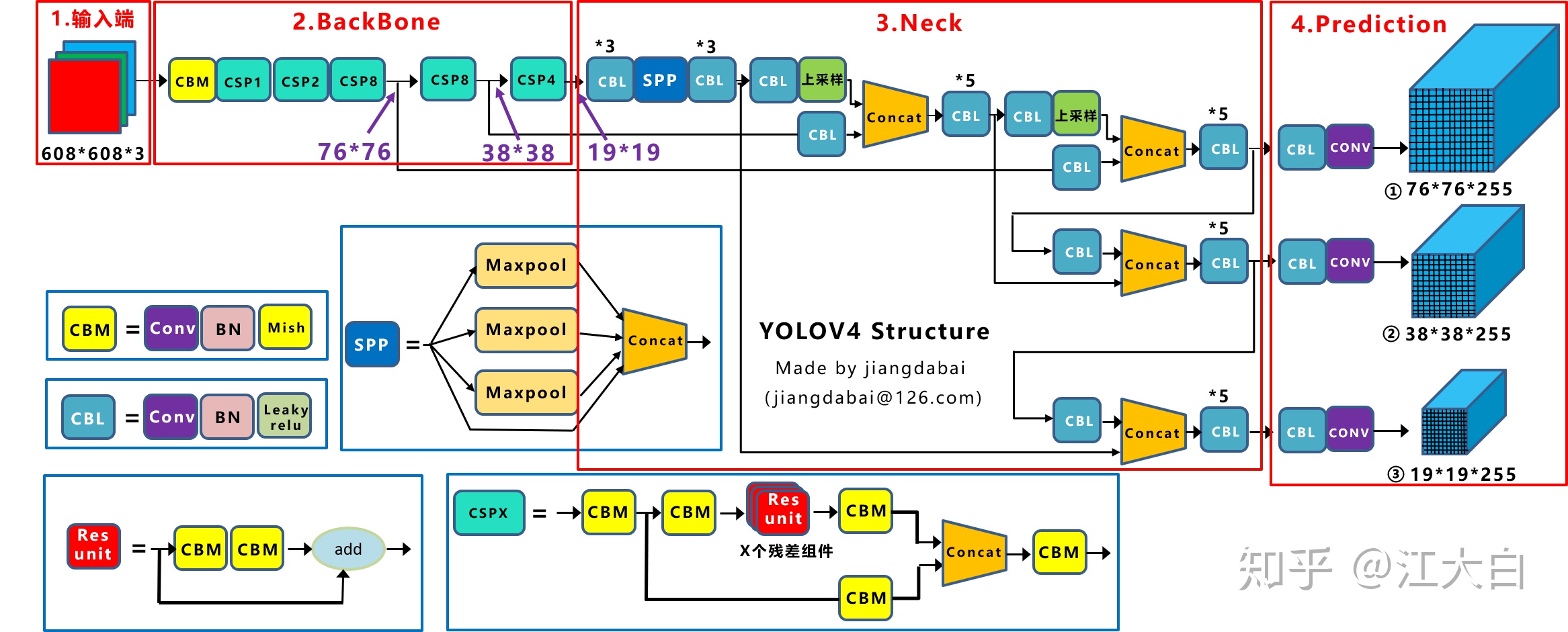
网络结构图
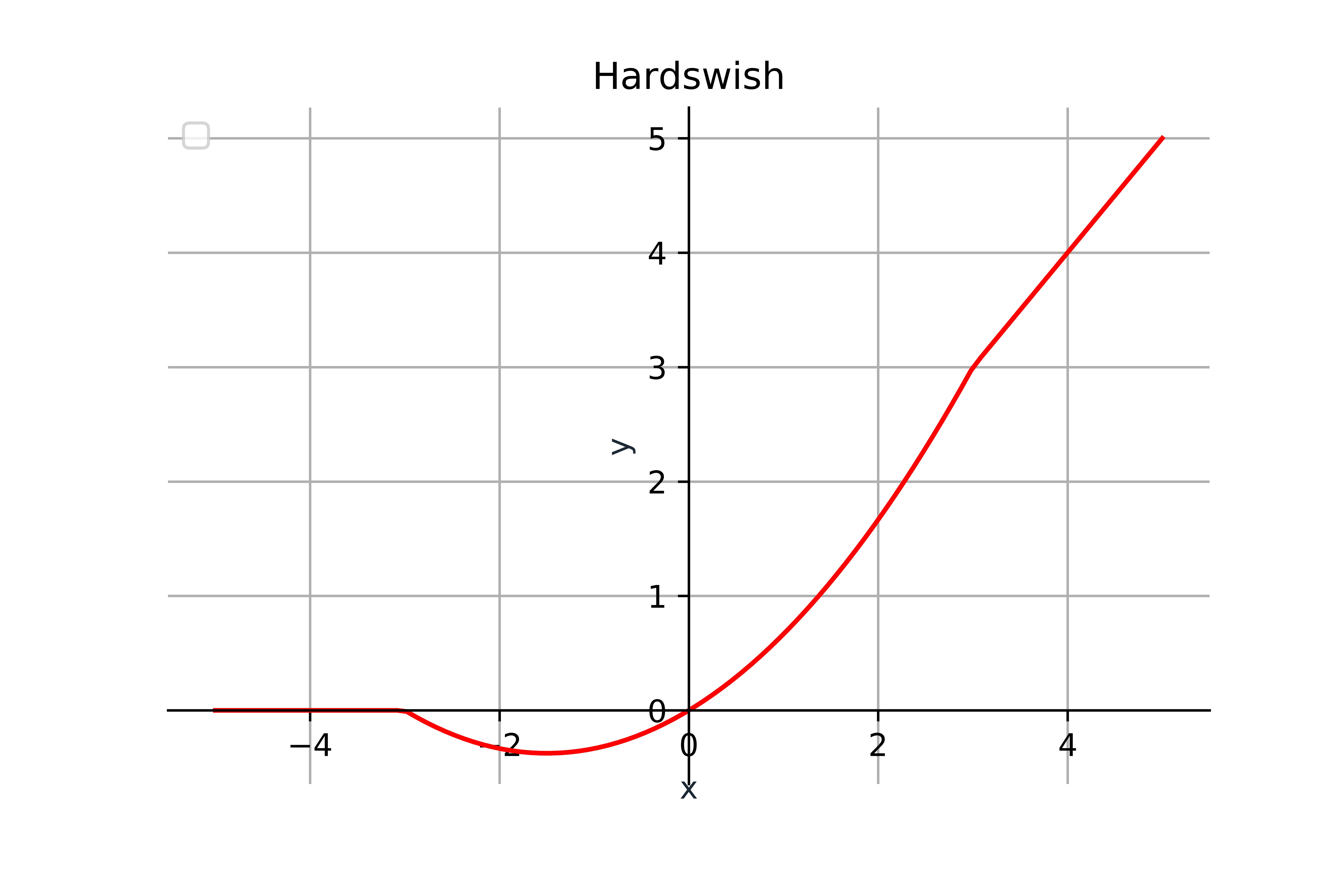
Hardswish $(x)=\left\{\begin{array}{ll}0 & \text { if } x \leq-3 \\ x & \text { if } x \geq+3 \\ x \cdot(x+3) / 6 & \text { otherwise }\end{array}\right.$
- 输入端:Mosaic数据增强、自适应锚框计算、自适应图片缩放
- Backbone:Focus结构,CSP结构
- Neck:FPN+PAN结构
- Prediction:GIOU_Loss
输入端
Mosaic数据增强
Mosaic数据增强采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接。


- 小目标的分布不均匀:Coco数据集中小目标占比达到41.4%,但在所有的训练集图片中,只有52.3%的图片有小目标,而中目标和大目标的分布相对来说更加均匀一些。
- 丰富数据集:随机使用4张图片,随机缩放,再随机分布进行拼接,大大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更好。
- 减少GPU:作者考虑到很多人可能只有一个GPU,因此Mosaic增强训练时,可以直接计算4张图片的数据,使得Mini-batch大小并不需要很大,一个GPU就可以达到比较好的效果。
自定义锚框
kmean + 遗传算法
antoanchor.py
自适应图片缩放
datasets.py的letterbox函数

Backbone
Focus结构
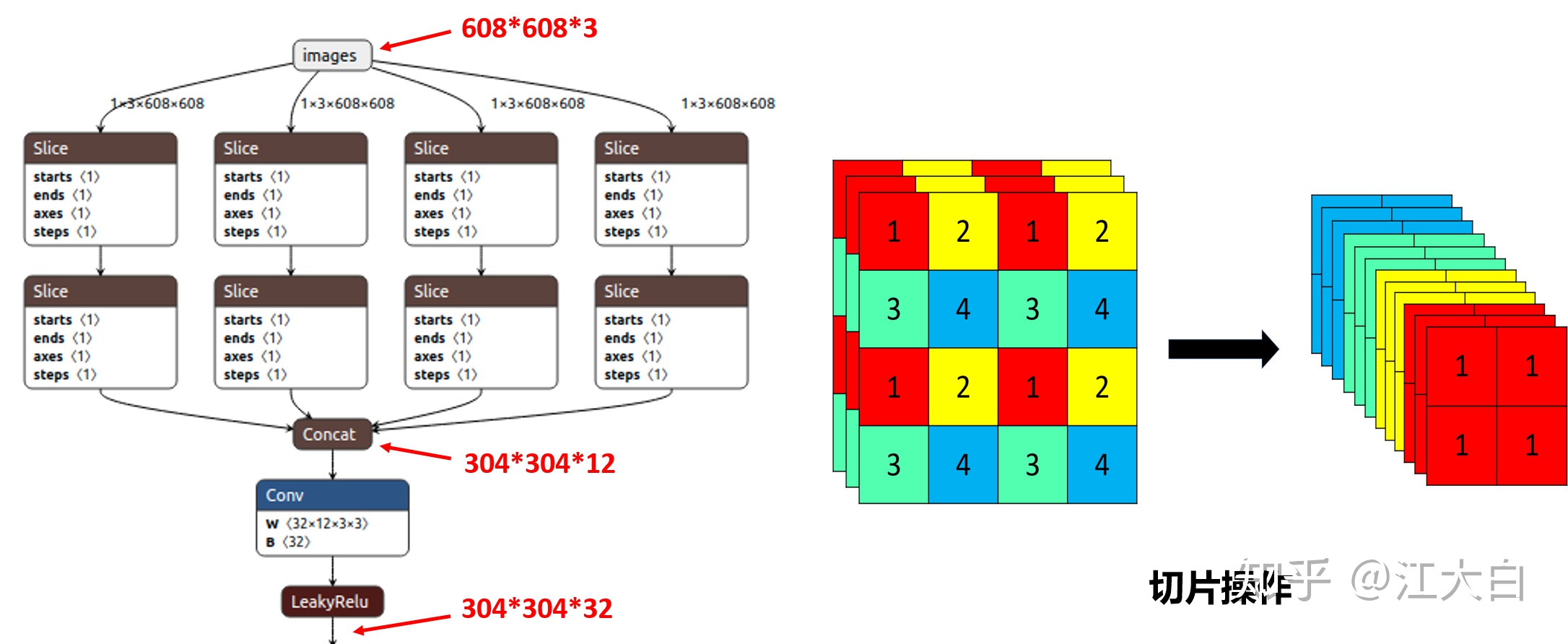
common.py的Focus函数
Neck
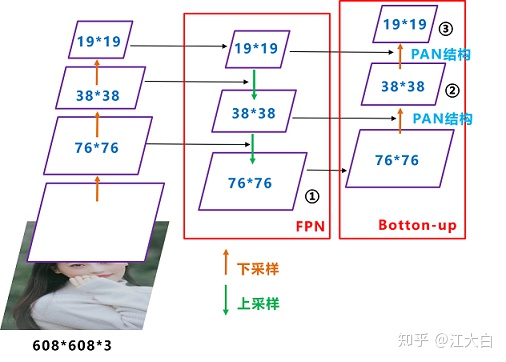
loss 计算
yolov5的loss设计和前yolo系列差别比较大的地方就是正样本anchor区域计算,其余地方差距很小。分类分支采用的loss是BCE,conf分支也是BCE,当然可以通过h[‘fl_gamma’]参数开启focal Loss,默认配置没有采用focal los,而bbox分支采用的是Ciou loss。
$b_x = 2\sigma(t_x) - 0.5$
$b_y = 2\sigma(t_y) - 0.5$
$b_w = 4\sigma^2(t_w)p_w$
$b_h = 4\sigma^2(t_h)p_h$
IOU_Loss
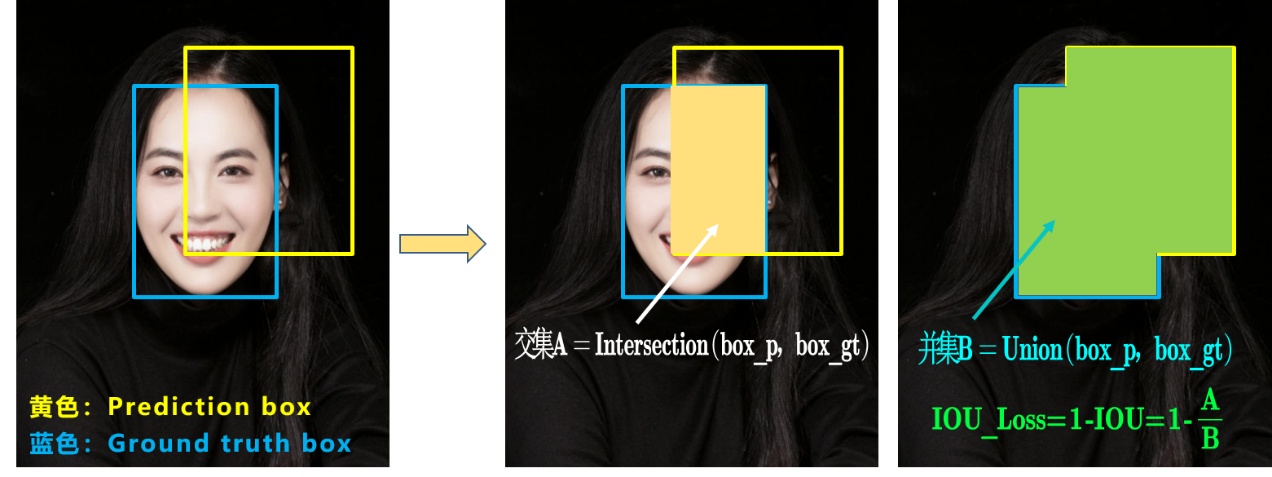

GIOU_Loss
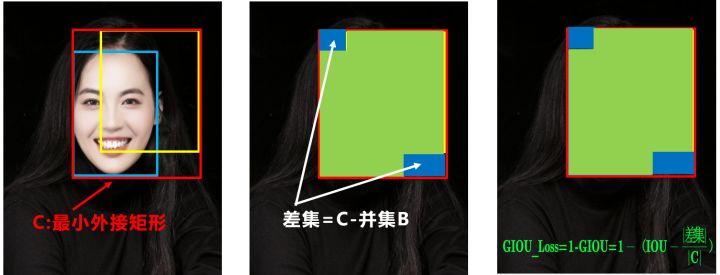

DIOU_Loss

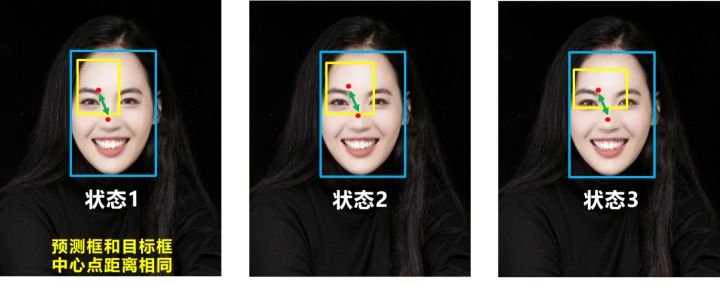
CIOU_Loss
效果